
Get early access

Building AI-driven agents has been a trial by fire. As a developer, I’ve faced busted demos, odd bugs, and “oh no” moments that taught me more than any success did. That’s why I wanted to put together a list of 10 hard-earned lessons from the trenches of developing AI agents – hopefully, they save you some headaches.

Generic AI models are tempting to use, but we learned that domain-specific data can make or break your project. Our first attempt used a broad pre-trained model with shallow, sometimes irrelevant results. Only after feeding it industry-specific datasets did the agent’s accuracy and context understanding drastically improve. This isn’t just anecdotal – experts note that the real competitive edge comes from leveraging private, domain-specific data, not just bigger models.
For instance, a legal AI agent trained on general web text will flounder on contract language, whereas one trained on a corpus of legal documents will excel. The takeaway: invest in curating data that’s highly relevant to your domain – your model’s performance will thank you.
In early projects, we gave our agent a hazy mission (“help with customer support” was one request) and ended up with an AI agent that went in circles. We learned quickly that without crystal-clear objectives, an AI agent will wander or fixate on the wrong problem. Define what you want the agent to accomplish in exact terms – e.g., “resolve at least 80% of user requests without human intervention” instead of “improve customer experience”. Vague goals are actually a top reason AI projects fail; one review put it bluntly: “No clear vision means no great value… to reap from your AI project”.
So nail down the use case, success metrics, and boundaries early. It’s way easier to hit a target you can actually see.
The best AI solutions we built were the ones that augmented humans, not replaced them. No matter how autonomous your agent is, plan for it to work hand-in-hand with people. In one case, our AI could draft analytic reports, but we had human experts review and tweak the final output – the combo was far more effective than AI or humans alone. Research backs this up: the real breakthrough lies in understanding where AI’s capabilities end and human strengths take over.
In practice, this means designing your system so that the AI handles the grunt work or first pass (data gathering, initial recommendations) and seamlessly passes control to a human for the nuanced judgment calls. Ignoring the human element isn’t just bad ethics or UX; it flat-out limits the effectiveness of your solution.
A slick AI demo means nothing if it slows your system to a crawl. I once built an agent that produced great results, but took 30 seconds and 100% CPU to do so – users gave up before it ever finished. Lesson learned: optimize for performance from day one. This might mean using smaller models, caching results, batching requests, or offloading heavy computation to a background job. As one engineering guide notes, always “optimize for speed, accuracy, and resource efficiency” when picking AI frameworks and architecture. In our projects, we set strict latency budgets for AI calls and monitored CPU/memory like hawks.
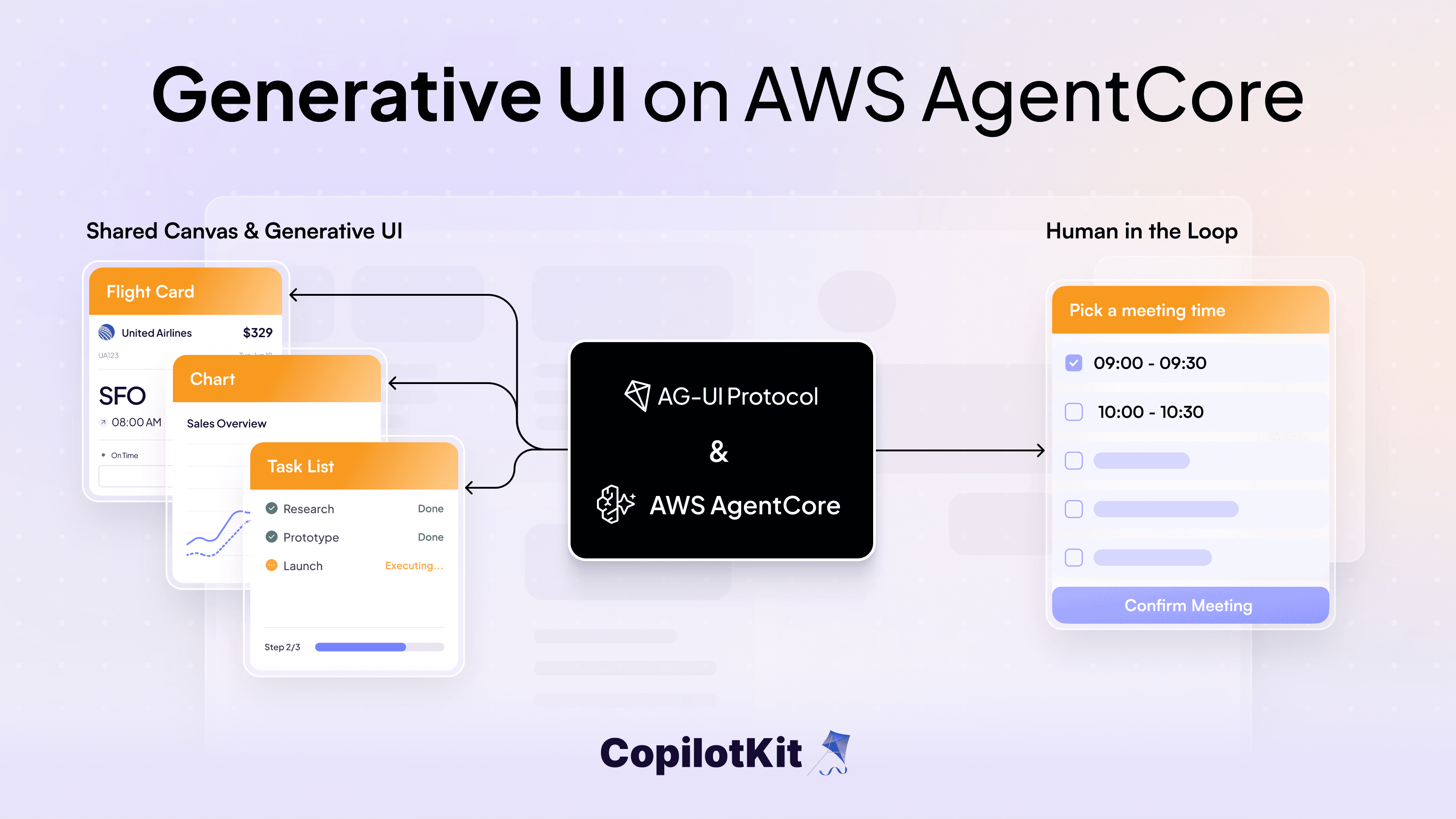
A good way to keep users engaged, even during a slow load is by introducing generative UI. What generative UI does is that it gives the user a feel of thinking alongside the AI model.
Here's an example of generative UI in action.
It’s not glamorously “AI” work, but it’s essential engineering. Fast, efficient responses keep users happy and your cloud bill under control, whereas an agent that’s too slow or resource-hungry will end up disabled, no matter how smart it is.
Hooking an AI agent into real data and systems is exciting – and risky. In one close call, our agent’s debug logs were unknowingly storing user input that included sensitive info. We now treat security and privacy as first-class requirements whenever AI is in the mix. That means baking in access control, encryption, and safety checks from the start. For example, our agent that manages cloud resources was confined to least-privilege IAM roles and had to get confirmation before executing any destructive action. We also sanitized logs and outputs to avoid leaking secrets. If your AI touches user data, ensure compliance with privacy laws (GDPR, HIPAA, etc.) and industry regulations – those aren’t optional either.
The bottom line is that an AI agent can introduce new security attack surfaces (prompt injection, data leakage) and privacy pitfalls. Address these early, or you’ll be patching scary holes in production (or worse, after an incident).
“Human-in-the-loop” sounds like a buzzword until you skip it and things go wrong. We discovered that having humans involved at key points is indispensable for training, refining, and governing our AI agents. One example: I built a content generator agent and quickly found it would drift off-topic or produce edgy outputs unless we continuously gave it feedback and corrections. Incorporating a review mechanism where humans regularly evaluate the AI’s results made a huge difference. Even the most advanced models like GPT-4 were fine-tuned with human feedback for better alignment.
A good way to achieve HITL is at the building stage of the agent. This is such that as the agent is being built, real-time human input and augmentation are being made.
To provide an example closer to the world of software engineering, consider an agent designed to answer a search query. Its cognitive architecture would mimic that of an actual human looking to solve or answer these queries itself, leveraging both broad knowledge and specific skills.
This visualization above provides a simplified representation of the agent workflow as defined in LangGraph, demonstrating how different components of the cognitive architecture are assembled together.
We’re used to unit tests and integration tests with deterministic outcomes. With AI, we had to rethink our testing approach entirely. Traditional software testing is relatively black-and-white (given X, expect Y), but an AI model’s output can be a spectrum of correct-ish answers. We learned to adopt a statistical and scenario-based testing mindset. Instead of expecting identical outputs, we focused on metrics like accuracy rates, error bounds, and consistency across many runs. One colleague summed it up: testing an AI system is more of a “volumes game, not a scenarios game.”
You need large sample sizes and varied cases to truly judge it. In practice, we built test harnesses that fed our agent hundreds of real-world queries, and then we manually inspected or computed how often it did the right thing. We also did adversarial testing (throwing weird or bad inputs at it) to see how it failed. And crucially, we tested the fallbacks – making sure that when the AI screws up, it fails safely (e.g., passes control to a human, returns an error message, etc.). Expecting 100% correctness from an AI is a recipe for disappointment; instead, test to know the limits and behavior patterns so you can manage them.
An AI agent will do exactly what you trained or prompted it to do – which isn’t always what you intended it to do. In our deployments, we ran into cases where the agent confidently made the wrong call. (Think of an AI customer service bot issuing an unprompted refund to a complainer – technically solving the problem, but not the way the business wanted.) The lesson: trust, but verify. We now build in mechanisms to intercept or override the agent’s decisions when needed. For critical actions, a human must give approval, or an extra rule-based check runs first. This aligns with best practices that say high-stakes decisions should always have a human in the loop
We also put thresholds on confidence levels – if the agent isn’t, say, 90% sure about an answer or action, it flags for review instead of acting. The key is not to be lulled by the AI’s apparent autonomy. Give it the freedom to handle the easy stuff, but always have an “emergency brake”. You’ll prevent disasters and sleep better at night.
Early on, we built an agent that chained API calls together brilliantly, yet it often fell on its face because it lacked context. It didn’t remember previous interactions and had no sense of the bigger picture state. The fix was giving our agent a form of memory and situational awareness. We let it store important facts from prior steps (what the user already asked, the current goal) and provided access to our app’s state. Most real-world AI agents can’t operate in a vacuum – they must integrate with external state (databases, user profiles, environment data) to be truly effective.
For example, an AI scheduling assistant should know the user’s existing calendar events (state) before suggesting a meeting time. Likewise, an agent controlling IoT devices needs to know the last known status of those devices. Don’t assume the AI will magically infer context it hasn’t been given. Be deliberate in feeding relevant context and maintaining memory across interactions. Without it, the agent is just blindly calling APIs and will make nonsensical or inefficient decisions.
Launching your AI agent isn’t the finish line – it’s the start of a long race. We noticed that models in production “drift” over time: a performance that was great at launch can degrade as fresh data comes in or users find edge cases. Whether it’s new slang confusing your chatbot, or evolving user preferences reducing a recommendation agent’s accuracy, something will change. The only cure is continuous learning and iteration. This means regularly updating the model with new training data, re-training or fine-tuning on a schedule, and monitoring performance in the wild. In our practice, we set up an automated pipeline to periodically retrain the agent on recent data (with proper evaluation before each redeploy). Industry guidance echoes this: retraining with new data isn’t optional – it “ensures that the model stays accurate and adapts to changes in the data distribution over time”.
Also, be ready to tweak prompts or rules as you observe new failure modes. Essentially, treat an AI agent as a living product that needs ongoing care. If you let it stagnate, it will become obsolete or error-prone while the real world moves on.
Building with AI agents is an exciting journey with its challenges.
The lessons we learned from our experiences can be highlighted in a simple theme: success with AI depends just as much on solid engineering practices, oversight, and iteration as it does on clever algorithms. For developers interested in building with reliable and efficient AI agents, applying these lessons will be greatly helpful to you.

Subscribe to our blog and get updates on CopilotKit in your inbox.
